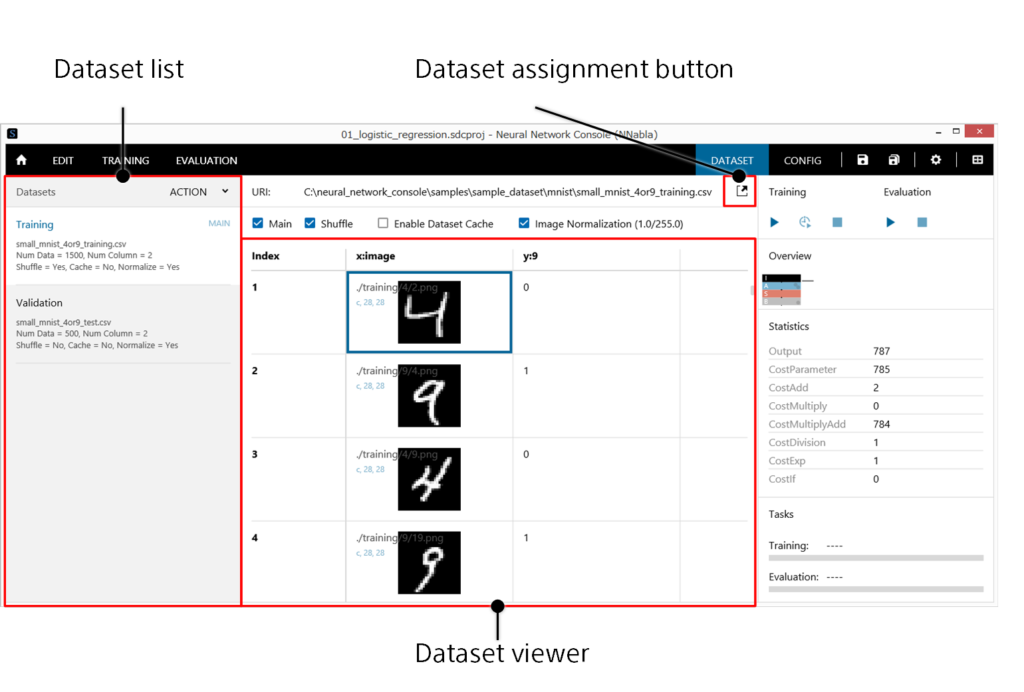
The dataset tab is used to specify and view the datasets that will be used in neural network training.
1 Specifying a CSV file containing training and validation datasets
- From the data list, select the dataset CSV file. As the name suggests, the default Training dataset is for training, and the Validation dataset is for validation.
- Click the Dataset Assignment button. In the dataset management window that appears, select the dataset.
2 Viewing the content of a dataset
- From the data list, select the dataset you want to view.
- View the content of the dataset in the dataset viewer area. The dataset viewer area shows the content of the specified dataset in tabular form.
Reference
Cells that image file names are assigned to show image previews. Cells that data CSV file names are assigned to show graphs of the matrix data (values on the vertical axis, rows on the horizontal axis, and columns shown with different color lines). If all images are CSV data, up to 248 rows and 10 columns of data are shown. If a value in the data CSV file is outside the -1.0 to 1.0 range, an overload message appears.
3 Specifying the dataset for determining the length of one epoch
- From the data list, select the dataset that will be used to determine the length of one epoch.
- Select the Main check box.
Reference
The number of data samples used for training in one epoch is determined based on the dataset specified for Main. For example, if dataset A containing 10000 data samples and dataset B containing 30000 data samples are used for training and the Main dataset is set to B, one epoch is assumed to be the point at which 30000 data points have been trained. With this setting, dataset A is used three times during one epoch of training.
4 Shuffling a dataset during execution
- From the data list, select the dataset you want to shuffle.
- Select the Shuffle check box.
Notes
Shuffling is performed in unit of cache files, which are created for every 100 data samples before a new training epoch begins, and between the 100 data samples in each cache file.
Make sure not to specify shuffling for the dataset used for validation performed with the Evaluation button. Validation performed with the Evaluation button requires the data order of the CSV file and that of the cache file to be the same.
5 Using previously created dataset cache to reduce the time it takes for training to begin
- From the data list, select the dataset you want to reuse from the cache.
- Select the Enable Dataset Cache box.
Notes
If the Enable Dataset Cache check box is selected and a dataset cache is available, the cache is always used. As such, even if the content of the dataset is updated, the existing cache is used without updating the cache. To update the content of the cache when the content of the dataset is updated, clear the Enable Dataset Cache check box, and execute training.
6 Scaling the brightness down by a factor of 255 and normalizing the input values in the range of 0.0 to 1.0 for image data included in a dataset before applying it to the neural network
- From the data list, select the dataset you want to normalize the image brightness of.
- Select the Image Normalization (1.0/255.0) check box.
Reference
Image normalization is processed by the CPU. When handling large image data, training performance may improve by setting Image Normalization to off and performing 1/255 scaling (set the Value property to 1/255 = 0.0039215686…) using the MulScalar layer, which can be processed with the GPU, instead.
7 Adding a new dataset
Click the hamburger menu (≡) or right-click the Dataset list to open a shortcut menu, and click Add.
8 Renaming a dataset
- Click the hamburger menu (≡) or right-click the Dataset list to open a shortcut menu, and click Rename.
- Alternatively, on the Dataset list, double-click the dataset you want to rename.
- Type the new name, and press Enter.
9 Deleting a dataset
- From the data list, select the dataset you want to delete.
- Click the hamburger menu (≡) or right-click the Dataset list to open a shortcut menu, and click Delete.
Or, press Delete on the keyboard.
10 Rearranging Datasets
- From the data list, select the dataset you want to rearrange.
- Click the hamburger menu or right-click the Dataset list to open a shortcut menu, and click Move Up or Move Down.
11 Selecting a specific cell in the dataset viewer
Click a cell you want to select.
Or, move the cursor in the dataset viewer using the arrow keys, Page Up, Page Down, Home, and End keys or mouse wheel (rotate only the mouse wheel to move vertically, rotate the mouse wheel while holding down Shift to move horizontally).
12 Moving the display range of the dataset viewer
Drag the scroll bars on the right and at the bottom of the dataset viewer.
Or, move the cursor outside the dataset viewer using the arrow keys, Page Up, Page Down, Home, and End keys or mouse wheel (rotate only the mouse wheel to move vertically, rotate the mouse wheel while holding down Shift to move horizontally).
Reference
If the dataset fits in one page, the vertical and horizontal scroll bars do not appear.
13 Opening a specific image or file in a dataset with an external app
Double-click a cell containing a file name.
Or, right-click a cell containing a file name to open a shortcut menu, and click Open.
Or, select a cell containing a file name, and press Enter.
14 Opening a folder containing a specific image or file in the dataset
Right-click a cell containing a file name to open a shortcut menu, and click Open File Location.
15 Saving the CSV file of a dataset with a different name
Right-click the dataset viewer to open a shortcut menu, and click Save CSV as.
16 Checking the consistency of a dataset
Right-click the dataset viewer to open a shortcut menu, and click Check Consistency.
Training and validation datasets are checked to determine whether the file names, number of variables, the size of each variable, etc. are properly set. If there are inconsistencies, the error locations and the description of the inconsistencies are shown.