Neural Network ConsoleではLIMEというプラグインが使えるのをご存じでしょうか?
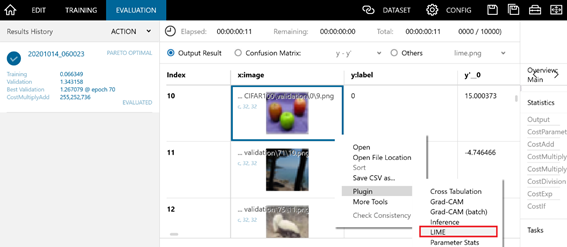
今回は、このLIMEについて紹介したいと思います。
【LIMEとは】
LIMEとは、機械学習モデルを用いて分類する際に、判断理由を説明するためのアルゴリズムです。判断に対する各特徴量の寄与度を算出します。LIMEを用いてモデルをデバッグすることで、モデルの信頼性を高めることができます。
今回はLIMEを画像分類に適用した例を見ていきましょう。LIMEを画像分類に適用する場合、寄与度の大きいピクセルのみをハイライトすることによって、「モデルが画像のどの部分を見て分類したのか」を視覚的に理解することができます。
例えば、以下の例は画像中で、リンゴという分類に寄与する部分をハイライトしたものです。提示された理由が合理的なのでこのモデルは信頼できそうだ、と言えるでしょう。

一方で、以下の画像のように、花である理由として葉がハイライトされたらどうでしょうか。このモデルの判断の理由は不合理なので、何らかの修正が必要そうです。このモデルは間違った学習の仕方をしているので、用いたデータに偏りが無いかや学習が収束しているかなどを確認してみてください。例えば、学習に用いた花の画像が背景に葉が写っているものばかりで、花以外の画像には葉が写っていなければ、「葉が写っていれば花なんだ!」と学習してしまうかもしれません。このようにLIMEを用いてモデルのデバッグをすることができます。

一方、同様にモデルの判断理由を説明するアルゴリズムとしてGrad-CAMというものがあり、こちらもNNCにプラグインとして実装されています。LIMEがGrad-CAMよりも優れているところとしては①多くのモデルに適用できる、②手法がわかりやすい、の2点があげられると思います。
Grad-CAMは、畳み込み層を持っているニューラルネットワークにしか使えませんが、LIMEは畳み込み層を持っていなくても使うことができます。また、LIMEの入出力を適切に変更することによって自然言語処理や時系列データ解析にも適用することができます。
加えて、LIMEは手法が非常に分かりやすいです。Grad-CAMは最後の畳み込み層が判断理由のデータを持っていると考え、そこから説明画像を作成する手法です。LIMEはモデルを局所的に線形モデルで近似し、重みが大きい部分をハイライトする手法です。LIMEのアルゴリズムについては記事後半の【LIMEのアルゴリズム】にてもう少し詳しく説明します。
【使い方】
Neural Network Consoleでは画像分類の際にLIMEのプラグインが使えるようになっています。(表データ版のLIMEも開発中です。)LIMEのプラグインの使い方を紹介します。処理が重いのでGPUを使うことを推奨します。
ここでは、サンプルプロジェクト「resnet-110.sdcproj」を用いて説明します。訓練、評価を終わらせた状態からLIMEを使う場合の流れは以下の通りです。
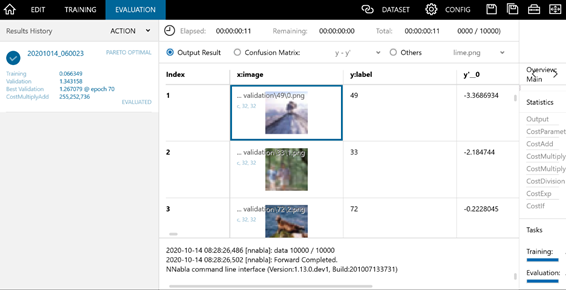
- 評価結果(EVALUATION)タブで右クリック -> Plugin -> LIMEを選択していきます。
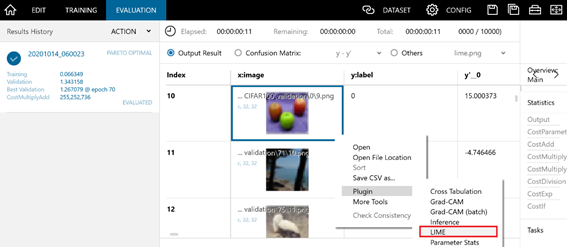
- 以下のように、LIMEを適用するにあたっての詳細な設定画面が出てきます。適宜設定を変えてから、ウィンドウ下部の「OK」を押すことでLIMEを実行することができます。(今回は何も設定を変えなくてもLIMEを実行することはできます。)
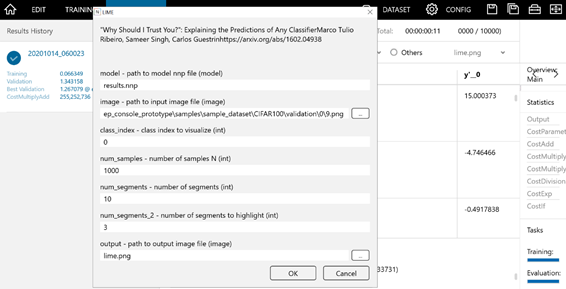
・modelでは、LIMEを適用するモデルの入っているファイルを選択します。基本的には変える必要はありません。
・「image」にはLIMEを設定する画像ファイルのパスを書きます。デフォルトでは、評価結果(EVALUATION)タブで選択していた画像のパスが入っています。Validation dataに含まれていない画像を選択することもできます。
・「class_idx」には、可視化を行うクラスのインデックスを書きます。デフォルト値は0です。サンプルプロジェクト「resnet-110.sdcproj」においてはインデックス0がリンゴに対応しているので、class_idxに0を設定しておくと、「リンゴである」という判断に寄与する画像領域がハイライトされることになります。
・「output」には、可視化結果を出力する画像ファイルの名前を書きます。
(他の設定項目については、記事の最後、【LIMEのアルゴリズム】で説明します。)
- 中央に結果が表示されます。
基本的な使い方としては以上ですが、モデルの出力結果を見て可視化を行うクラスを決めたい場合もあると思います。上の例では評価結果(EVALUATION)タブの画像の横にモデルの出力結果が出ているため、それを見て判断することができます。一方、画像がvalidation dataに含まれていない場合やダウンロードした学習済みモデルを使う場合には、「Inference」というプラグインを用いて画像に対して推論を行い、その結果を見て判断することができます。
【LIMEのアルゴリズム】
NNCにおけるLIMEのアルゴリズムの流れは以下の通りです。
- 入力画像をいくつかのセグメント(いくつに分割するかをLIMEのオプションnum_segmentsで指定します)に分割します。
- 入力画像のセグメントにランダムにマスクをかけた画像を複数生成します(いくつ生成するかをLIMEのオプションnum_samplesで指定します)。この画像をtraining data、この画像に対する元のモデルのアウトプットをラベルとして、線形モデルで回帰を行います。この時、1における入力画像の各セグメントの有無を特徴量としてとらえています。よって、ここで学習させる線形モデルの入力の次元は入力画像のセグメント数と一致します。
- 2で学習させた線形モデルの重みが各セグメントの寄与度であると解釈し、線形モデルの重みが上位のセグメントをハイライトした元画像を出力します(寄与度が上位何番目のセグメントまでハイライトするかをnum_segments_2で指定します)。
・セグメンテーション手法について
NNCでは入力する画像をセグメントに分割する際にはskimageを用いています。skimageにはセグメンテーション手法としてfelzenszwalb, slic, quickshift, watershedの4つが用意されています[1]。 4つの手法のうち、現在NNCで使えるのはslicのみです。なお、セグメンテーション手法によってLIMEの結果が大きく変わる場合があることが報告されています[2]。
プラグインのオプションnum_segmentsはskimage.segmentation.slicに引数として渡されています。slicの仕様上、指定したセグメント数と実際のセグメント数が異なることがあります。それに伴いnum_segments_2で指定した数と実際にハイライトされたセグメントの数が異なることがあります。また、モデルがきちんと学習できていない場合には、稀にどこのセグメントもハイライトされないこともあります。
【参考文献】
[1] Comparison of segmentation and superpixel algorithms
[2] Ludwig Schallner, Johannes Rabold, Oliver Scholz, Ute Schmid. Effect of Superpixel Aggregation on Explanations in LIME — A Case Study with Biological Data. arXiv preprint arXiv: 1910.07856.
https://arxiv.org/abs/1910.07856
[3] Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin. “Why Should I Trust You?” Explaining the Predictions of Any Classifier. arXiv preprint arXiv:1602.04938.
https://arxiv.org/abs/1602.04938
[4] The CIFAR-100 dataset