Neural Network Consoleでは複数のGPUを用いた学習により、学習に要する時間を大幅に短縮することができます。マルチGPUを用いた学習時に高い精度を実現するためには、シングルGPUでの学習時との動作の違いを理解しておく必要があります。
ここでは、シングルGPU学習とマルチGPU学習の違いと、シングルGPU時とほぼ同じ学習結果を実現するために必要な設定について解説します。
1 シングルGPU学習とマルチGPU学習の違い
Neural Network ConsoleでシングルGPU(もしくはCPU)を用い学習を実行した場合の動作は以下の通りです。
- 1epochの間にデータセットのデータ数÷Batch Size回以下の動作を行う
- CONFIGタブ、Global ConfigのBatch Sizeで指定した数のデータをデータセットから取得
- 取得したデータを用いてニューラルネットワークのパラメータの勾配を計算(Forward/Backward)
- 求めた勾配を用いてニューラルネットワークのパラメータを更新(Update)
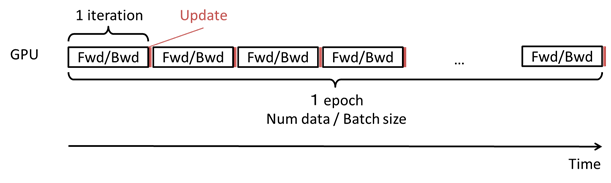
シングルGPU(もしくはCPU)を用い学習を実行した場合の動作
これに対し、Neural Network Consoleで複数のGPUを用いた学習を行う場合の動作は以下の通りです。
- 1epochの間にデータセットのデータ数÷(Batch Size×GPU数)回以下の動作を行う
- CONFIGタブ、Global ConfigのBatch Sizeで指定した数のデータをデータセットから各GPU用に取得(1つのGPUあたりBatch Size個、合計Batch Size × GPU個のデータが取得される)
- 各GPUで、取得したデータを用いてニューラルネットワークのパラメータの勾配を計算(Forward/Backward)
- 求めた勾配を全てのGPU間で平均(Sync)
- GPU間で平均化した勾配を用いてニューラルネットワークのパラメータを更新(Update)
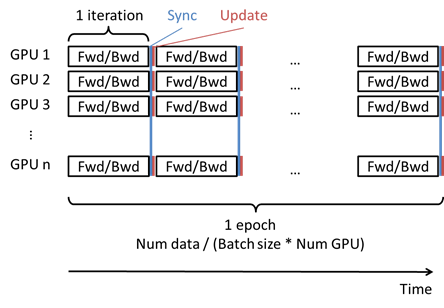
複数のGPUを用いた学習を行う場合の動作
マルチGPUを用いた場合、1回のパラメータの更新(Update)に用いられるデータの数は、シングルGPUを用いた場合のGPU数倍になっていることが分かります。つまり、マルチGPUを用いた場合、論理Batch Size(シングルGPUでの学習に換算した場合のBatch Size)は、CONFIGタブ、Global ConfigのBatch Sizeで指定した数のGPU数倍になります。
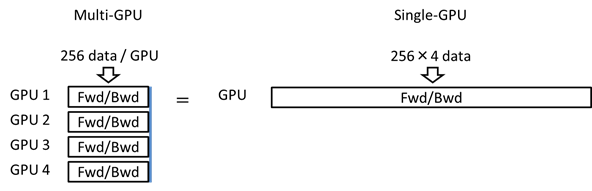
例:Batch Size 256、4台のGPUで学習を行う場合、論理Batch Sizeは256×4=1024となる
2 マルチGPU学習において、シングルGPU時とほぼ同じ学習結果を得るために必要な設定
全く同じプロジェクトを元にシングルGPUとマルチGPUで学習を行った場合、GPUの数により論理Batch Sizeが変化する影響で、学習結果に差分が生じます。マルチGPU学習において、シングルGPU時とほぼ同じ学習結果を得るためには、以下のいずれかの方法で学習時のパラメータを変更する必要があります。
- マルチGPU学習時の論理Batch SizeをシングルGPU学習時のBatch Sizeに合わせる
- 論理Batch Sizeの変化に合わせて、Learning Rateを調整する(おすすめ)
以下でそれぞれについて具体的な設定方法を解説します。
2.1 マルチGPU学習時の論理Batch SizeをシングルGPU学習時のBatch Sizeに合わせる
CONFIGタブ、Global ConfigのBatch Sizeを、GPUの数で割ります。
例:シングルGPU時のBatch Sizeが256、4台のGPUで学習を行う場合、Batch Sizeを1/4の64とすることで、論理バッチサイズを64×4=256とする。
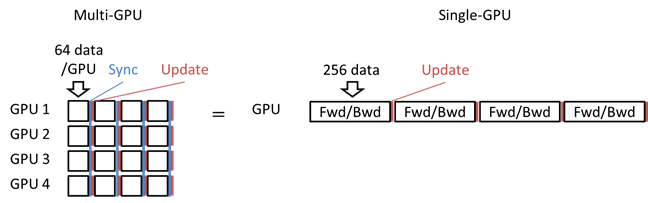
例:論理バッチサイズを64×8=256とする
メリット
- 論理バッチサイズがシングルGPU学習時と同一になるため、ほぼ同じ学習結果が得られる可能性が高い
デメリット
- GPU間でパラメータを交換する頻度が大きくなるため、学習速度が低下する
- 例えばBatch Sizeを1/4した場合、GPU間のパラメータの交換頻度は4倍となる
- GPU間のパラメータの交換が完了するまでの間、GPUは次の処理を行えないため学習速度が低下する
- GPUで一度に処理するデータ数が少なくなるため、学習速度が低下する
- GPUでは一度にまとめてたくさんのデータを処理させたほうが高速な処理が期待できる
- 一度に処理するデータ内での平均、分散を用いるBatchNormalizationでは、Batch Sizeの違いにより処理結果に差分が生じる
- 特にBatch Sizeが16以下など極端に小さくなる時には注意が必要
2.2 論理Batch Sizeの変化に合わせて、Learning Rateを調整する(おすすめ)
CONFIGタブ、OptimizerのLearning Rate(Adamの場合Alpha)を、GPU数倍します。
例:シングルGPU時のLearning Rateが0.1、4台のGPUで学習を行う場合、Learning Rateを4倍の0.4とする。
メリット
- GPU間でパラメータを交換する頻度を低く保てるため、学習が高速
- GPUで一度に処理するデータ数を大きく保てるため、学習が高速
デメリット
- 論理Batch Sizeが大きくなりすぎると、収束性が悪化しシングルGPUと同じ学習結果を得られなくなることがある
2.3 その他、注意点
CONFIGタブ、OptimizerのLearning Rate Multiplierを利用している(1より小さい値を指定している)場合、マルチGPU学習時、CONFIGタブ、Optimizer、LR Update Intervalの値は学習実行時に自動的にGPU数で割られます。マルチGPU学習時においては、論理Batch SizeがGPU数倍になる影響で1 epochあたりのIterationは1/GPU数になるため、これを補正する(データ数あたりのLearning Rate更新回数をシングルGPU学習時と同一にする)ものです。 元のLR Update IntervalがGPU数より小さい場合、手動でLearning Rate Multiplierを設定し直す必要があります。