1.プラグインの使い方
前処理プラグイン
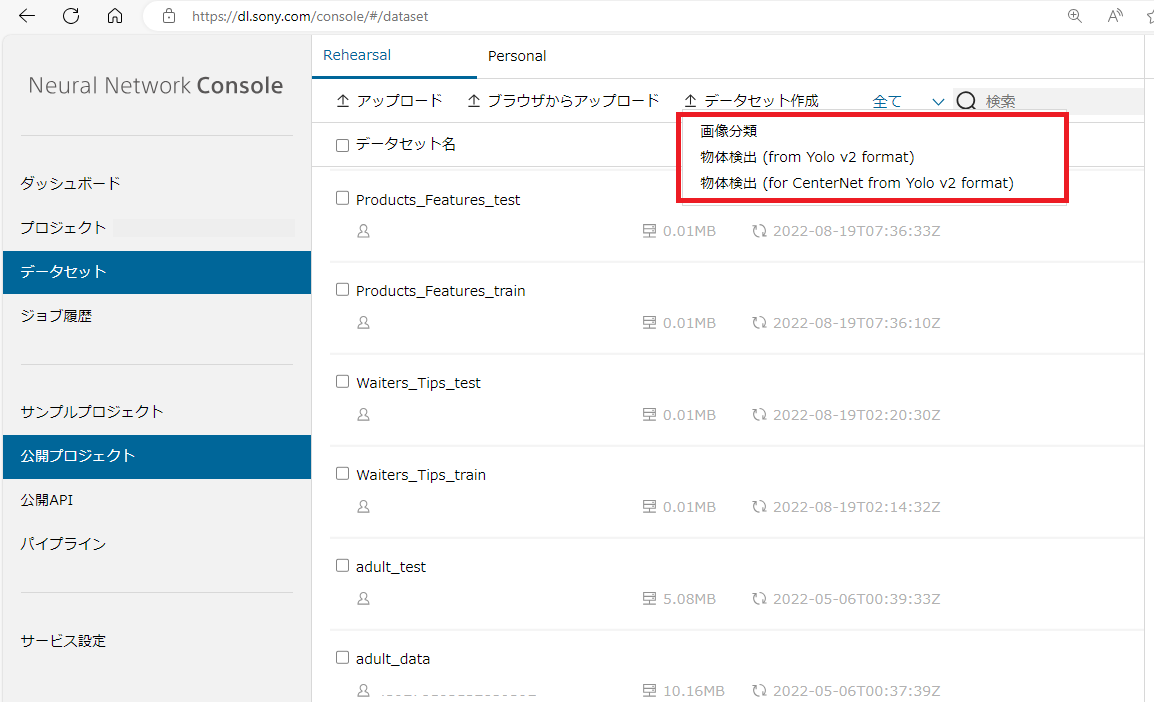
前処理ブラグインはデータセット画面において、データセット作成をクリックし、適用したいプラグインを選択することでご利用いただけます。
後処理プラグイン
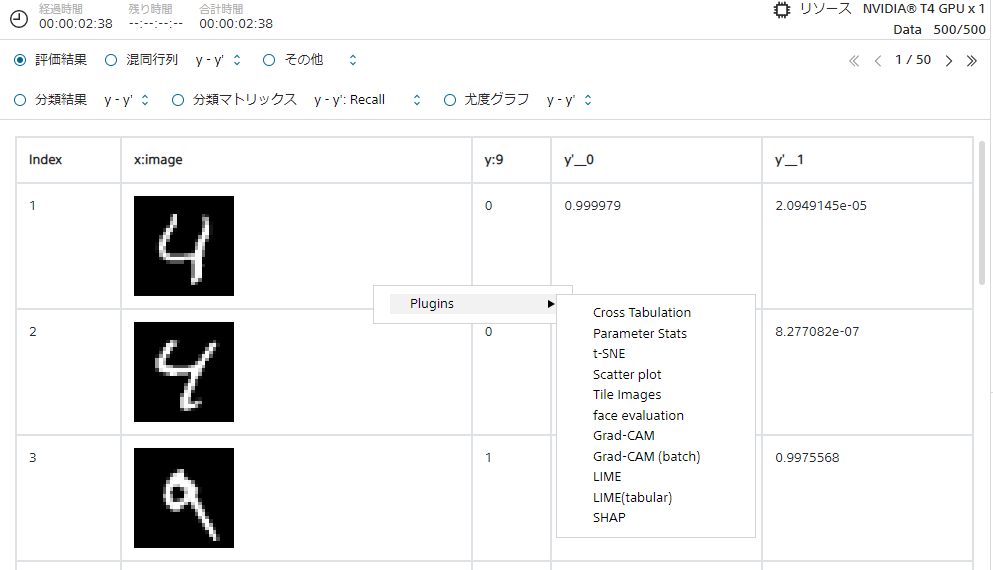
後処理プラグインは評価タブで、プラグインを適用したい画像にカーソルを合わせ右クリック → Plugins → 適用したいプラグインを選択することでご利用いただけます。
学習プラグイン
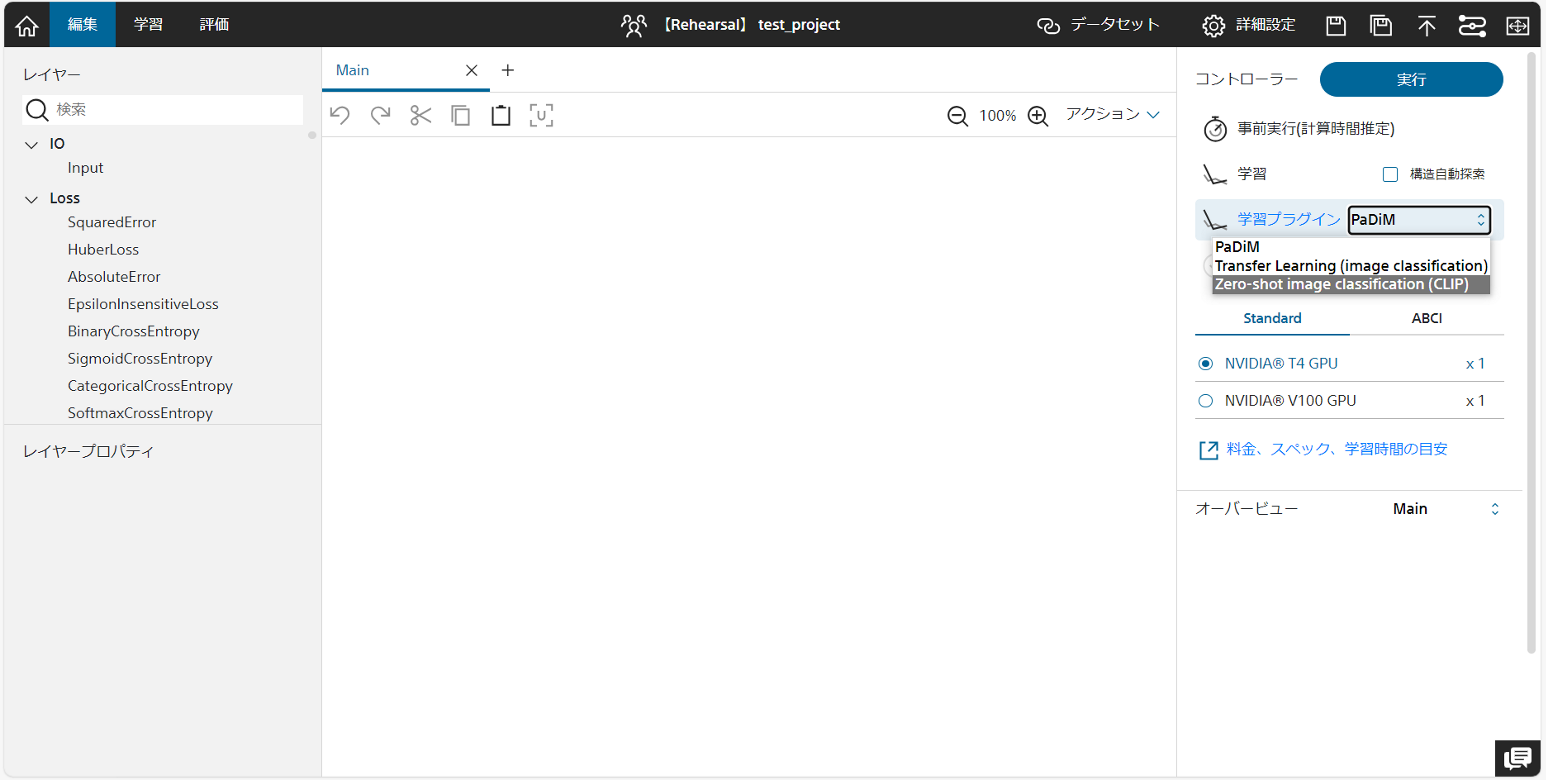
学習プラグインは編集タブで、「実行」ボタン下の「学習プラグイン」タブより表示されたプルダウンメニューを選択することでご利用いただけます。
2.クラウド版で利用できるプラグイン
前処理プラグイン
・画像分類
・物体検出(from Yolo v2 format)
・物体検出(for CenterNet from Yolo v2 format)
後処理プラグイン
・Cross Tabulation
・Parameter Stats
・t-SNE
・Scatter plot
・Tile Images
・face evaluation
・Grad-CAM
・Grad-CAM(batch)
・LIME
・LIME(tabular)
・SHAP
学習プラグイン
・PaDiM
・Transfer Learning
・Zero-shot image classification (CLIP)
・PatchCore
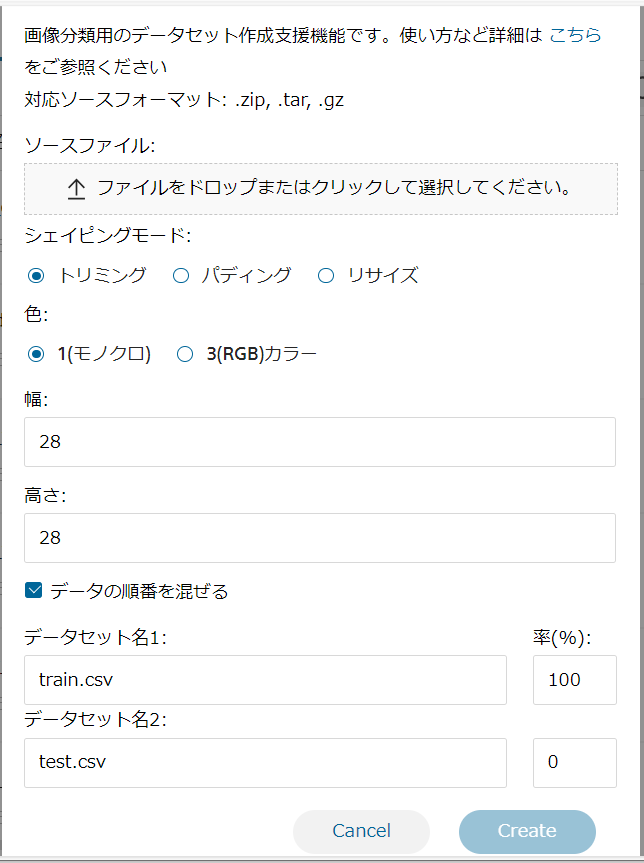
■画像分類 について
画像分類の概要
画像分類用のデータセットを、Neural Network Console のデータセット CSVファイル形式、特に画像分類のサンプルプロジェクトで用いている形式にコンバートします。
| ソースファイル | 変換元の画像ファイルを選択します。 |
| シェイピングモード | 3種類のシェイピングモードから一つを選択します。 変換元データセットに含まれる画像のアスペクト比が width, height で指定するサイズのアスペクト比と異なる場合、アスペクト比を合わせる方法を指定します。 トリミング:画像の端を切り取ることでアスペクト比を合わせます。 パディング:画像の端に 0 を挿入することでアスペクト比を合わせます。 リサイズ:アスペクト比を無視し、画像を指定サイズにリサイズします。 |
| 色 | コンバート後のデータセットの画像チャンネル数を 1(モノクロ)もしくは 3(RGB)で指定します。 |
| 幅 | コンバート後のデータセットの画像の幅をピクセル単位で指定します。 |
| 高さ | コンバート後のデータセットの画像の高さをピクセル単位で指定します。 |
| データの順番を混ぜる | データの並び順をシャッフルする場合はチェックを行います。 |
| データセット名1 | 学習用に利用するデータ名および割合を選択します。 |
| データセット名2 | 評価用に利用するデータ名および割合を選択します。 |
画像分類画面
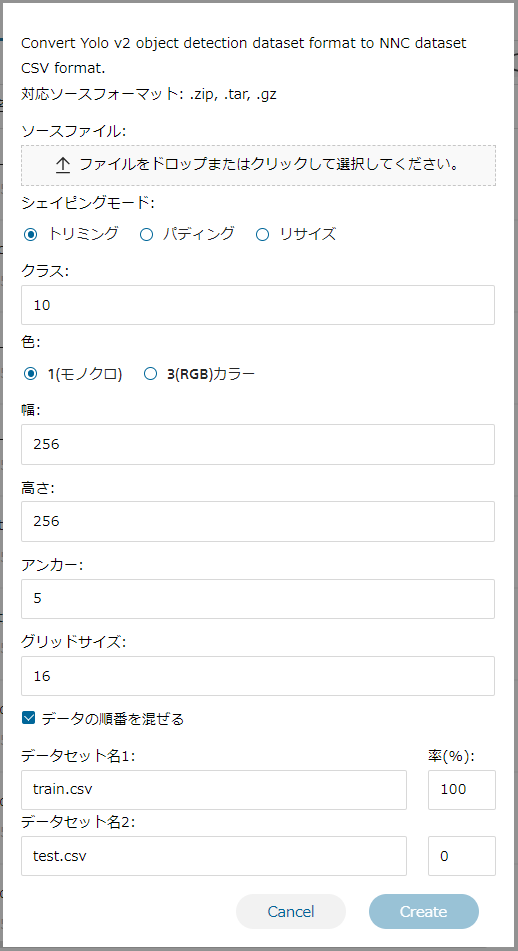
■物体検出(from Yolo v2 format)について
物体検出(from Yolo v2 format)の概要
Yolo v2 フォーマットで準備された物体検出データセットを、Neural Network Console のデータセット CSVファイル形式、特に物体検出サンプルプロジェクト、synthetic_image_object_detection で用いている形式にコンバートします。
Yolo v2 フォーマットは、画像ファイルと同名かつ拡張子を txt に変更したファイル名のテキストファイルを用意し、テキストファイルの各行に物体のIndex、中心 X 座標、中心 Y 座標、幅、高さを入力します。物体の Index は 0 から始まる整数で、座標及び縦横のサイズは画像の左上を (0.0, 0.0)、画像の右下を (1.0,1.0)として指定します。
| ソースファイル | 変換元の画像ファイルを選択します。 |
| シェイピングモード | 3種類のシェイピングモードから一つを選択します。 変換元データセットに含まれる画像のアスペクト比が width, height で指定するサイズのアスペクト比と異なる場合、アスペクト比を合わせる方法を指定します。 トリミング:画像の端を切り取ることでアスペクト比を合わせます。 パディング:画像の端に 0 を挿入することでアスペクト比を合わせます。 リサイズ:アスペクト比を無視し、画像を指定サイズにリサイズします。 |
| クラス | 変換元データセットに含まれる検出対象の物体の総数(テキストファイルに含まれる物体 Index の最大値+1)を指定します。 |
| 色 | コンバート後のデータセットの画像チャンネル数を 1(モノクロ)もしくは 3(RGB)で指定します。 |
| 幅 | コンバート後のデータセットの画像の幅をピクセル単位で指定します。 |
| 高さ | コンバート後のデータセットの画像の高さをピクセル単位で指定します。 |
| アンカー | アンカーの数(物体検出を行う基礎となる縦横比、サイズのバリエーション数)を指定します。 |
| グリッドサイズ | width, height で指定した画像を構成するグリッドのサイズをピクセル単位で指定します。width, height は grid-size で割り切れる必要があります |
| データの順番を混ぜる | データの並び順をシャッフルする場合はチェックを行います。 |
| データセット名1 | 学習用に利用するデータ名および割合を選択します。 |
| データセット名2 | 評価用に利用するデータ名および割合を選択します。 |
物体検出(from Yolo v2 format)画面
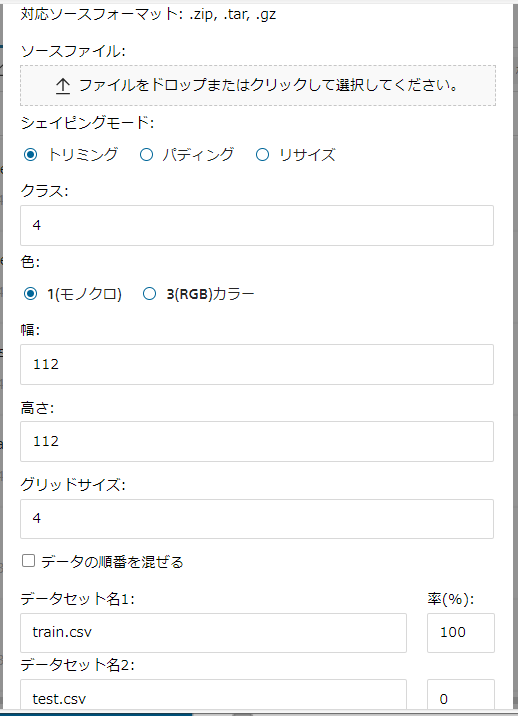
■物体検出(for CenterNet from Yolo v2 format)について
物体検出(for CenterNet from Yolo v2 format)の概要
Yolo v2 フォーマットで準備された物体検出データセットを、Neural Network Console のデータセット CSVファイル形式、特にCenterNetを用いた物体検出サンプルプロジェクトで用いている形式にコンバートします。
| ソースファイル | 変換元の画像ファイルを選択します。 |
| シェイピングモード | 3種類のシェイピングモードから一つを選択します。 変換元データセットに含まれる画像のアスペクト比が width, height で指定するサイズのアスペクト比と異なる場合、アスペクト比を合わせる方法を指定します。 トリミング:画像の端を切り取ることでアスペクト比を合わせます。 パディング:画像の端に 0 を挿入することでアスペクト比を合わせます。 リサイズ:アスペクト比を無視し、画像を指定サイズにリサイズします。 |
| クラス | 変換元データセットに含まれる検出対象の物体の総数(テキストファイルに含まれる物体 Index の最大値+1)を指定します。 |
| 色 | コンバート後のデータセットの画像チャンネル数を 1(モノクロ)もしくは 3(RGB)で指定します。 |
| 幅 | コンバート後のデータセットの画像の幅をピクセル単位で指定します。 |
| 高さ | コンバート後のデータセットの画像の高さをピクセル単位で指定します。 |
| グリッドサイズ | width, height で指定した画像を構成するグリッドのサイズをピクセル単位で指定します。width, height は grid-size で割り切れる必要があります |
| データの順番を混ぜる | データの並び順をシャッフルする場合はチェックを行います。 |
| データセット名1 | 学習用に利用するデータ名および割合を選択します。 |
| データセット名2 | 評価用に利用するデータ名および割合を選択します。 |
物体検出(for CenterNet from Yolo v2 format)画面
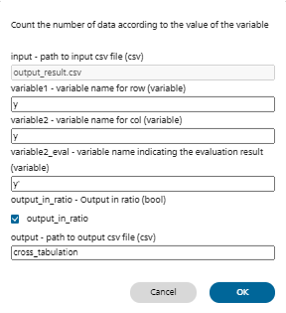
■Cross Tabulationについて
Cross Tabulationの概要
データセットCSVフォーマットのファイルに対するクロス分析を行います。ラベル毎のデータ数の集計、精度の算出などに用いることができます。
| input | 処理対象のデータセットCSVファイルを指定します 評価タブの出力結果から評価結果のCSVファイルに対するクロス分析を行うには、デフォルトのoutput_result.csvを使用します |
| variable1 | クロス分析結果の表の行に使用する変数名を指定します |
| variable2 | クロス分析結果の表の列に使用する変数名を指定します |
| variable2_eval | Variable2で指定した変数に対し精度評価を行った結果(正解/不正解)をクロス分析結果の表の列に使用する場合、variable2との比較に利用する変数名を指定します 例えば、画像分類における正解ラベル「y」と、ニューラルネットワークによる推定結果「y’」を比較した結果をクロス分析結果の表の列とするには、variable2に「y」、variable2_evalに「y’」を指定します 空白を指定するとクロス分析結果の表の列にはvariable2で指定した値がそのまま用いられます |
| output_in_ratio | 行ごとに対して1になるような割合を出力するかどうかを指定します チェックを行わなかった場合はデータ数がそのまま各セルの値として出力されます。 |
| output | クロス分析結果を出力するCSVファイルのファイル名を指定します 評価タブの出力結果からクロス集計を実行した場合、学習結果フォルダに指定したファイル名でクロス集計結果が保存されます |
Cross Tabulation画面
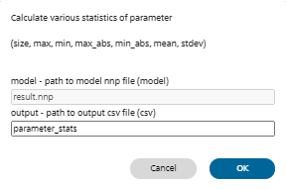
■Parameter Statsについて
Parameter Statsの概要
学習済みモデルに含まれるパラメータの各種統計値(サイズ、最大値、最小値、絶対値の最大値、絶対値の最小値、絶対値、平均、標準偏差)を算出します。
| model | 統計値を算出するモデルファイル(*.nnp)を指定します 評価タブで選択中の学習結果を元に統計値を算出するには、デフォルトのresults.nnpを使用します |
| output | 統計値を出力するCSVファイルのファイル名を指定します 評価タブの評価結果からParameter Statsを実行した場合、学習結果フォルダに指定したファイル名で統計値をまとめた表が保存されます |
Parameter Stats画面
■t-SNEについて
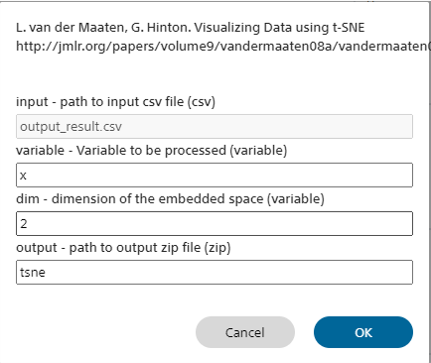
t-SNE概要
データセットCSVファイルに含まれる指定した変数のt-SNEを計算します。
Visualizing Data using t-SNE
- van der Maaten, G. Hinton.
http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
| input | t-SNEの演算を行う変数の含まれるデータセットCSVファイルを指定します |
| variable | t-SNEの演算を行う変数名を指定します |
| dim | t-SNEの次元数を指定します |
| output | inputのデータセットCSVファイルにt-SNE結果の列を追加したデータセットCSVファイルを出力するCSVファイルのファイル名を指定します評価タブの評価結果からt-SNEを実行した場合、学習結果フォルダに指定したファイル名で保存されます |
t-SNE画面
■Scatter plotについて
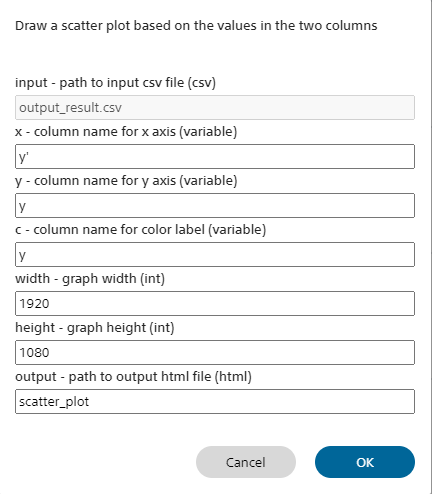
Scatter plot概要
x、y、cの3つの変数を使って、3次元の散布図を描画します。
xとyは各データ点を2次元のどの座標にプロットするかを決めるもの、cは色を決めるものです。
| input | 散布図の描画に用いるデータセットCSV ファイルを指定します。 評価タブの出力結果に基づき散布図を描画するには、デフォルトのoutput_result.csv を使用します。 |
| x | inputで指定したデータセット CSV ファイルに含まれる変数のうち、散布図の X 軸に使用する変数名を指定します。 |
| y | inputで指定したデータセット CSV ファイルに含まれる変数のうち、散布図の Y 軸に使用する変数名を指定します。 |
| c | inputで指定したデータセット CSV ファイルに含まれる変数のうち、散布図のカラーラベルに使用する変数名を指定します。 |
| width | 描画する散布図の横幅をピクセル単位で指定します。 |
| height | 描画する散布図の縦幅をピクセル単位で指定します。 |
| output | 出力するhtmlファイル名を指定します。 |
Scatter plot画面
■Tile Imagesについて
Tile Imagesの特徴
入力CSVファイルに含まれる画像をタイル状に並べた画像を作成します。誤って分類した画像を一覧で表示する用途などに利用することができます。
| input | 画像ファイル名の含まれるデータセットCSVファイルを指定します 評価タブの出力結果に含まれる画像を並べた画像を作成するには、デフォルトのoutput_result.csvを使用します 誤って分類した画像など、出力結果を絞り込んだ結果を元に処理を行うには、一旦右クリックメニューから絞り込み結果をCSVファイルとして保存し、保存したCSVファイルのファイル名をinputに指定します |
| variable | inputで指定したデータセットCSVファイルに含まれる変数のうち、並べる画像の含まれる変数名を指定します 指定しない場合、inputで指定したCSVファイルにファイル名が含まれる全ての画像が処理対象になります |
| image_width | 入力画像1枚の幅を指定します。指定しない場合は最初の1枚の画像の幅が用いられます 入力画像のサイズがimage_widthで指定したサイズと異なる場合、画像の横幅はimage_widthで指定した値にリサイズされます |
| image_height | 入力画像1枚の高さを指定します。指定しない場合は最初の1枚の画像の高さが用いられます 入力画像のサイズがimage_heightで指定したサイズと異なる場合、画像の横幅はimage_heightで指定した値にリサイズされます |
| num_column | 画像を並べる列数を指定します 出力画像の横幅の最大値は、image_width × num_columnになります |
| start_index | 並べて表示する最初のデータのIndexを指定します |
| end_index | 並べて表示する最後のデータのIndexを指定します end_index – start_index + 1枚の画像が並べて表示されます end_indexを指定しない場合、inputで指定したCSVファイルに含まれる全てのデータに含まれる画像が表示対象になります |
| output | タイル画像を出力する画像ファイルのファイル名を指定します 評価タブの評価結果からTile Imagesを実行した場合、学習結果フォルダに指定したファイル名でタイル画像が保存されます |
Tile Images画面

■face evaluationについて
Face evaluationの特徴
ITA(Individual Typology Angle)と呼ばれるスコアを算出し、顔画像の肌の色を数値化します。
Input Information
| input | ITAスコアの算出を行う対象の画像ファイル一覧を含むデータセットCSVファイルを指定します |
| output | 評価結果を出力するCSVファイルのファイル名を指定します |
output Information
| ITA | 対象のインスタンスのITAスコアを表します。ITAスコアが高いほど肌の色が白く、低いほど肌の色が黒いことを示します。 |
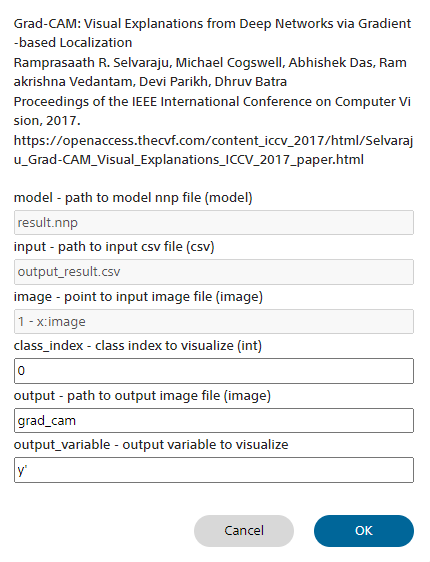
■Grad-CAMについて
Grad-CAMの概要
画像分類を行うConvolutional Neural Networksにおいて、分類結果に影響を及ぼす入力画像の箇所を可視化します。
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra Proceedings of the IEEE International Conference on Computer Vision, 2017.
https://openaccess.thecvf.com/content_iccv_2017/html/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.html
output_variableoutputのValidation列を指定します
| model | Grad-CAMの演算に用いるConvolutional Neural Networksのモデルファイル(*.nnp)を指定します 評価タブで選択中の学習結果を元にGrad-CAMを行うには、デフォルトのresults.nnpを使用します |
| image | 分析を行う画像ファイルを指定します。 評価タブの評価結果で表示されている特定の画像に対してGrad-CAMを行うには、画像ファイル名の係れたセルが選択された状態でプラグインを起動することで、imageに画像ファイル名が自動入力されます |
| class_index | 可視化を行うクラスのIndexを指定します デフォルトでは0番目のクラスに対する可視化を実行します |
| output | 可視化結果を出力する画像ファイルのファイル名を指定します 評価タブの評価結果からGrad-CAMを実行した場合、学習結果フォルダに指定したファイル名で可視化結果が保存されます |
Grad-CAM画面
■Grad-CAM(batch)について
Grad-CAM(batch)の概要
画像分類を行うConvolutional Neural Networksにおいて、分類結果に影響を及ぼす入力画像の箇所を可視化します。
Grad-CAMプラグインが1枚の画像に対して処理を行うのに対し、Grad-CAM(batch)プラグインは指定するデータセットに含まれる複数枚の画像に一括して処理を行います。
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra Proceedings of the IEEE International Conference on Computer Vision, 2017.
https://openaccess.thecvf.com/content_iccv_2017/html/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.html
output_variableoutputのValidation列を指定します
| input | Grad-CAM処理を行う対象の画像ファイル一覧を含むデータセットCSVファイルを指定します 評価タブの出力結果に含まれる画像データに対しGrad-CAM処理を行うには、デフォルトのoutput_result.csvを使用します |
| model | Grad-CAMの演算に用いるConvolutional Neural Networksのモデルファイル(*.nnp)を指定します 評価タブで選択中の学習結果を元にGrad-CAMを行うには、デフォルトのresults.nnpを使用します |
| input_variable | inputで指定したデータセットCSVファイルに含まれる変数より、Grad-CAM処理対象の画像の変数名を指定します |
| label_variable | inputで指定したデータセットCSVファイルに含まれる変数より、可視化を行うクラスのIndexの変数名を指定します |
| output | 可視化結果を出力するデータセットCSVファイルのファイル名を指定します 評価タブの評価結果からGrad-CAMを実行した場合、学習結果フォルダに指定したファイル名で可視化結果が保存されます |
Grad-CAM(batch)画面

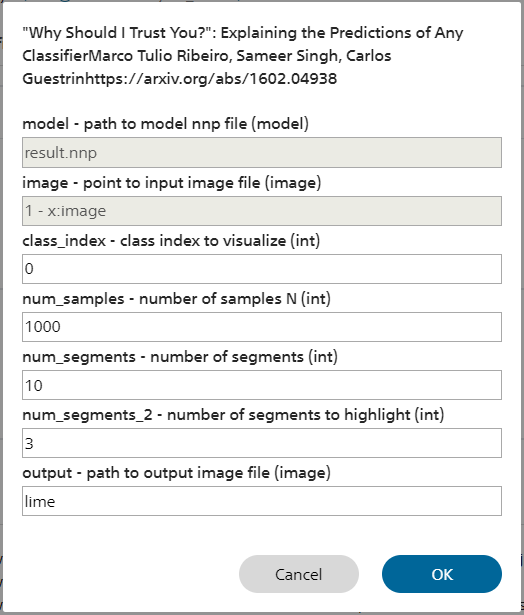
■LIMEについて
LIMEの概要
LIMEと呼ばれる手法を用い、画像分類を行うモデルにおいて、分類結果に影響を及ぼす入力画像の箇所を可視化します。
Why Should I Trust You? : Explaining the Predictions of Any Classifier Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin
https://arxiv.org/abs/1602.04938
| model | LIMEの演算に用いるモデルファイル(*.nnp)を指定します 評価タブで選択中の学習結果を元にLIMEを行うには、デフォルトのresults.nnpを使用します |
| image | 分析を行う画像ファイルを指定します。 評価タブの評価結果で表示されている特定の画像に対してLIMEを行うには、画像ファイル名の係れたセルが選択された状態でプラグインを起動することで、imageに画像ファイル名が自動入力されます |
| class_index | 可視化を行うクラスのIndexを指定します デフォルトでは0番目のクラスに対する可視化を実行します |
| num_samples | 入力画像と認識結果の関係をサンプリングする回数を指定します |
| num_segments | 入力画像を分割するセグメントの数を指定します |
| num_segments_2 | num_segmentsに分割された領域のうち、可視化するセグメントの数を指定します |
| output | 可視化結果を出力する画像ファイルのファイル名を指定します 評価タブの評価結果からLIMEを実行した場合、学習結果フォルダに指定したファイル名で可視化結果が保存されます |
LIME画面
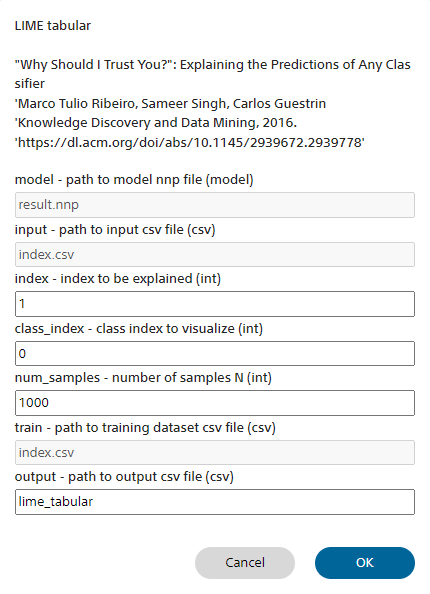
■LIME(tabular)について
LIME(tabular)の概要
LIME と呼ばれる手法を用い、テーブルデータを用いた分類を行うモデルにおいて、ある分類結果に関する入力データの各特徴量の寄与を、各特徴量の不等式とその寄与度として表します。回帰モデルや、特徴量にカテゴリ変数を含む分類モデルにも対応しています。
Input Information
| model | LIMEの演算に用いるモデルファイル(*.nnp)を指定します 評価タブで選択中の学習結果を元にLIMEを行うには、デフォルトのresults.nnpを使用します |
| input | LIME 処理を行う対象のデータを含むデータセットCSVファイルを指定します |
| index | input のCSVファイル内における、対象データの Index を指定します。 |
| class_index | 分析を行うクラスの Index を指定します デフォルトでは 0 番目のクラスに対する分析を実行します 回帰、二値分類ではclass indexは0のみ有効です |
| num_samples | n入力データと分類結果の関係をサンプリングする回数を指定します |
| train | モデルの学習時に用いたデータ一覧を含むデータセットCSVファイルを指定します |
| output | 結果を出力するCSVファイルのファイル名を指定します デフォルトでは lime_tabular.csv です。 |
Output Information
本プラグインの実行結果は ‘output’ で指定した名前のCSVファイルとして出力されます。 CSVファイル内の各行と各カラムに関しての情報は以下の通りです。 ‘Sample (Index {n})’ の行は各特徴量の値に対応します( ‘評価’ の結果得られる output_result.csvと同様の意味です)。 ‘Importance’ の行は、分類結果における各特徴量の寄与度を表します。’Importance’ の行の上の行は、その寄与度を与える際の各特徴量の不等式を示します。
LIME(tabular) 画面
■SHAPについて
SHAPの概要
SHAP と呼ばれる手法を用い、画像分類を行うモデルにおいて、分類結果に 影響を及ぼす入力画像の箇所を可視化します。
Input Information
| image | 分析を行う画像ファイルを指定します 評価タブの評価結果で表示されている特定の画像に対して SHAP を行うには、 画像ファイル名の書かれたセルが選択された状態でプラグインを起動するこ とで、image に画像ファイル名が自動入力されます |
| input | SHAP 処理を行う対象の画像ファイル一覧を含むデータセットCSVファイルを指定します 評価タブの Output Result に含まれる画像データに対しSHAP 処理を行うには、デフォルトの output_result.csv を使用しますし |
| model | SHAP 処理の演算に用いるモデルファイル(*.nnp)を指定します 評価タブで選択中の学習結果を元に SHAP 処理を行うには、デフォルトのresults.nnp を使用します |
| class_index | 可視化を行うクラスの Index を指定します デフォルトでは 0 番目のクラスに対する可視化を実行します。 |
| num_samples | 入力画像と認識結果の関係をサンプリングする回数を指定します |
| batch_size | SHAP 処理の際のbatch_sizeです |
| interim_layer | モデルを構成する層の内、input層以外の層に対してSHAP 処理を行う際に指定します input層を0番目として、何番目の層に関して SHAP 処理を行うか指定します デフォルトではinput層に対して処理が行われます |
| output | 可視化結果を出力する画像ファイルのファイル名を指定します デフォルトでは shap.png です |
Output Information
本プラグインの実行結果は ‘output’ で指定した名前のPNGファイルとして出力されます。 対象のインスタンスへの本プラグインの適用結果が表示されます。 分類において、正の影響を及ぼした箇所が赤色、負の影響を及ぼした箇所が青色として、元画像上に重ねて表示されます。
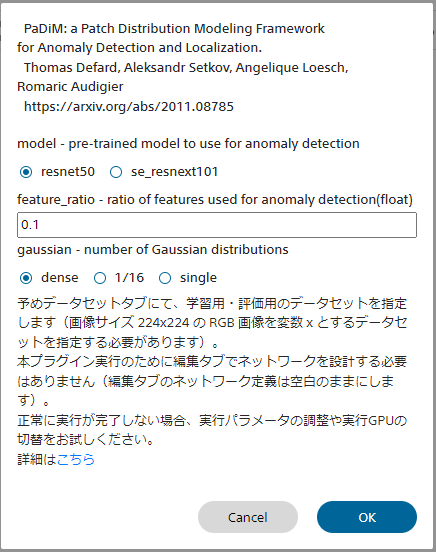
■PaDiMについて
PaDiM概要
画像の異常検知手法の1つであるPaDiMを用い、画像異常検知モデルの学習を行います。
PaDiMを用いることで、高性能な異常検知モデルを正常画像のみを用い高速に学習することができます。
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
Thomas Defard, Aleksandr Setkov, Angelique Loesch, Romaric Audigier
https://arxiv.org/abs/2011.08785
PaDiMを実行するには、予めデータセットタブにて変数xとして画像サイズ224×224のRGB画像を指定した学習用、評価用データセットを読み込みます。
ここで、学習用データセットには正常画像のみを含むようにします。
また、CONFIGタブのGlobal Configにてバッチサイズの設定を行います。
本プラグイン実行のために編集タブでネットワークを設計する必要はありません(編集タブのネットワーク定義は空白のままにします)。
| model | 異常検知に用いる学習済みモデルを選択します |
| feature_ratio | 異常検知に用いる学習済みモデルの中間特徴量の割合を指定します 50%の特徴を用いるには、0.5を指定します |
| gaussian | マハラノビス距離計算に用いるガウス分布を求める粒度を指定しますdense Layer1(最も解像度の高い特徴マップ)のピクセル毎にガウス分布を求めます。PaDiMの論文通りの動作になります 1/16 Layer3(最も解像度の低い特徴マップ)のピクセル毎にガウス分布を求めます。denseと比較しモデルのサイズをやや節約することができます single 画像全体で1つのガウス分布のみ用います。denseと比較しモデルのサイズを大きく節約することができます |
PaDim画面
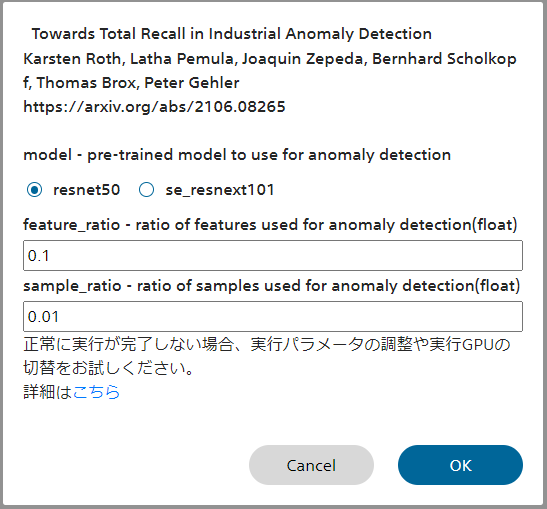
■PatchCoreについて
PaDiM概要
画像の異常検知手法の1つであるPatchCoreを用い、画像異常検知モデルの学習を行います。
PatchCoreを用いることで、高性能な異常検知モデルを正常画像のみを用い高速に学習することができます。
PatchCoreを実行するには、予めデータセットタブにて変数xとして画像サイズ224×224のRGB画像を指定した学習用、評価用データセットを読み込みます。
ここで、学習用データセットには正常画像のみを含むようにします。
また、CONFIGタブのGlobal Configにてバッチサイズの設定を行います。
本プラグイン実行のために編集タブでネットワークを設計する必要はありません(編集タブのネットワーク定義は空白のままにします)。
| model | 異常検知に用いる学習済みモデルを選択します |
| feature_ratio | 異常検知に用いる学習済みモデルの中間特徴量の割合を指定します 50%の特徴を用いるには、0.5を指定します |
| sample_ratio | 異常検知に用いるサンプルの割合を指定します |
PatchCore画面
■Transfer Learningについて
Transfer Learning 概要
学習済みモデルを利用し、高性能な画像分類モデルを高速に学習する転移学習を行います。
Transfer Learningを実行するには、予めデータセットタブにて変数xとして正方形のRGB画像を、変数yとして0から始まるクラスラベルを指定した学習用、評価用データセットを読み込みます。
また、CONFIGタブのGlobal Configにて学習反復世代数、バッチサイズの設定を、Optimizerにて最適化アルゴリズムの設定を行います。
本プラグイン実行のために編集タブでネットワークを設計する必要はありません(編集タブのネットワーク定義は空白のままにします)。
| model | 転移学習に用いる学習済みモデルを選択します |
| train_param | 学習するパラメータを指定しますall 全てのレイヤーのパラメータを学習します(Fine Tuning) last_fc_only ほとんどのレイヤーのパラメータは固定し、画像分類モデル最後の全結合層のパラメータのみを学習します |
Transfer Learning画面
![]()
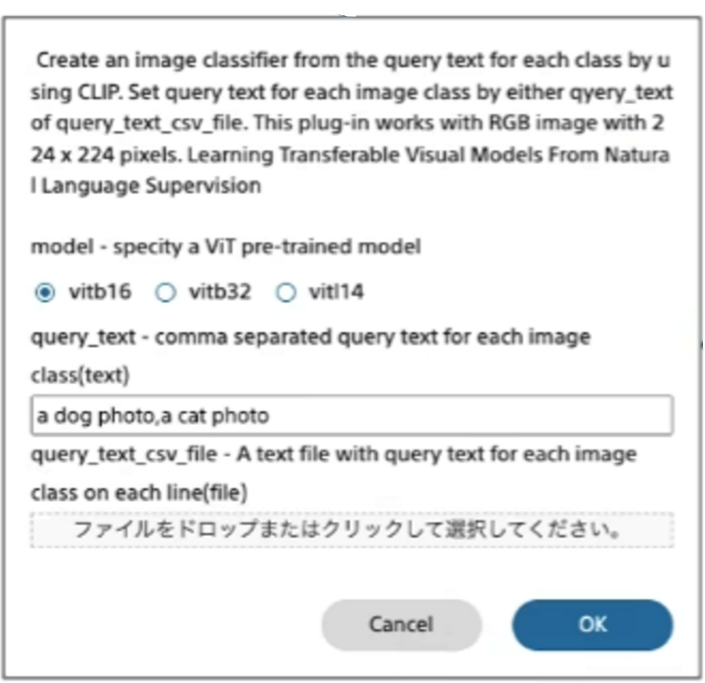
■Zero-shot image classification (CLIP) について
Zero-shot image classification (CLIP) の概要
学習を行う必要なく、入力文字列で指定されたファイルを、文字列で指定するラベルに従い分類します。
分類対象のラベルをカンマ区切りのテキストで指定することで学習過程なしに分類モデルを作成します。
例えば画像を花と食べ物に分類するには「flower,food」を指定します。
| model | 3タイプのViT事前学習モデルから一つを選択します。 |
| query_text | 分類したい対象クラスをテキストで指定します。各クラスはカンマで区切ります。 |
| query_text_cvs_file | 分類クラスをcsv形式のファイルで指定します。 |
Zero-shot image classification (CLIP) 画面