ここではパイプライン自動化の使い方について説明します。
パイプラインについて
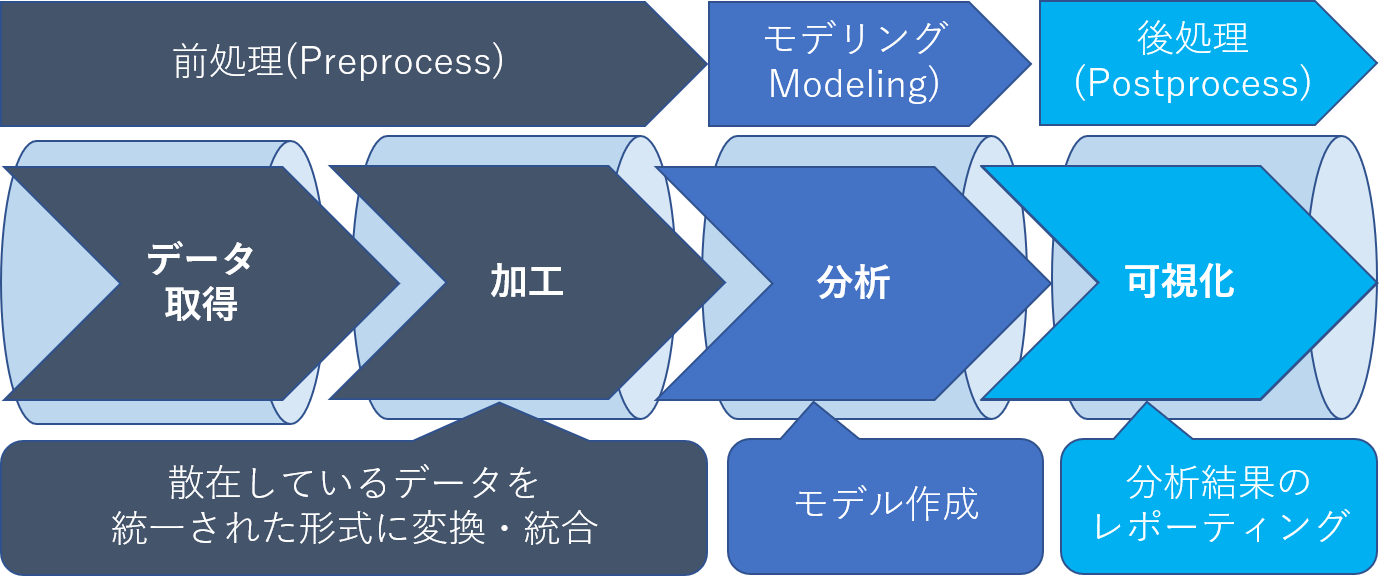
データ投入から評価結果の表示までのデータに関する一連の流れをパイプラインといいます。
パイプライン処理を自動化することはデータ前処理から結果の確認までの機械学習サイクルを効率化する手段となります。
パイプラインの作成
既に作成したプロジェクト(本手順ではサンプルプロジェクトのtutorial.basics.01_logistic_regressionを使用)を開き、
パイプラインのロゴを押してください。
![]()
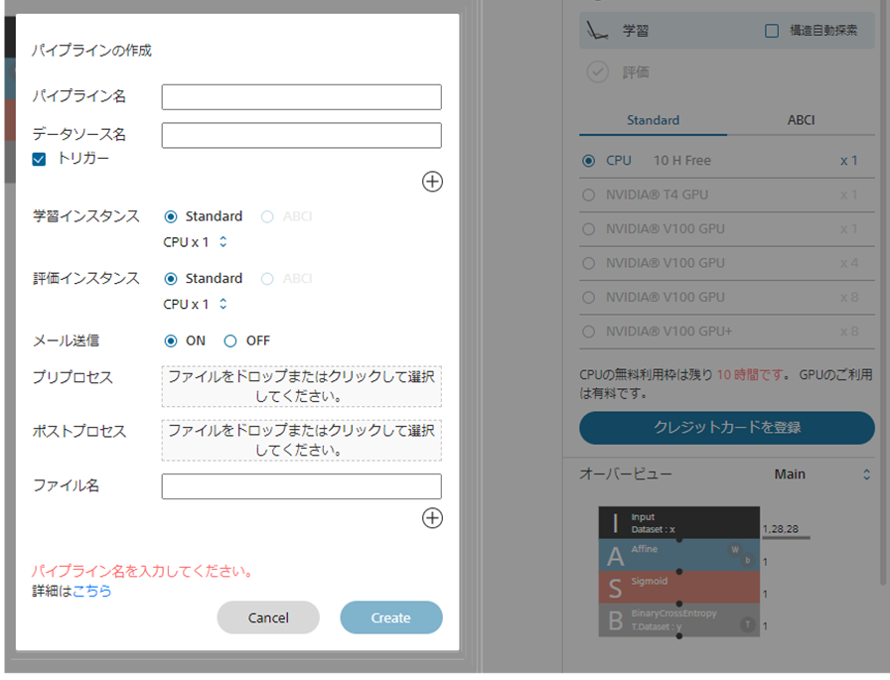
「パイプラインの作成」と表示されたダイアログが表示されたら、
パイプライン名、使用するデータソース名を入力します。
(ここで入力するデータソースのファイル形式は.tarのみ利用可能となります。)
学習時のインスタンスタイプ、評価時のインスタンスタイプを選択します。
ここまでが必須パラメータとなり、パイプライン作成に最低限必要なものとなります。
tarファイルについてはこちらをご覧ください。
任意パラメータの入力とデータソースのアップロード
任意のパラメータとしては、
プリプロセス、ポストプロセス、ファイル名があります。
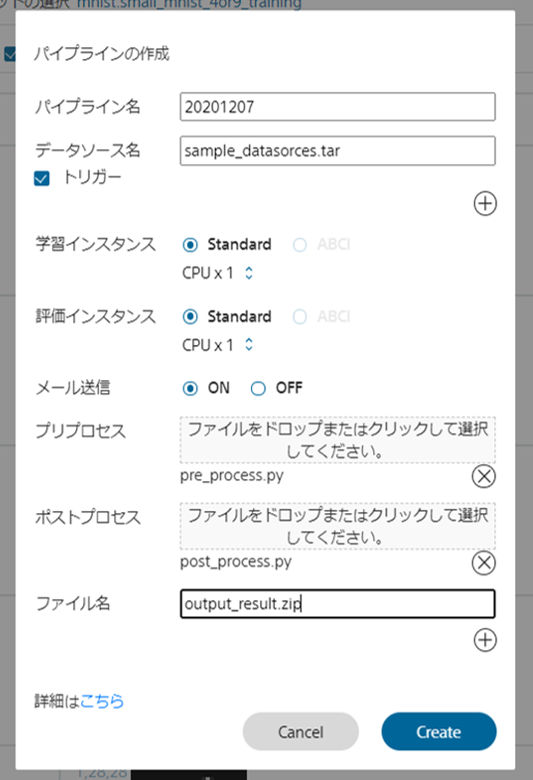
プリプロセスはデータソースを作成する処理を記述したファイルをアップロードすることで任意のデータソースを利用することができます。
対して、ポストプロセスは処理後の結果を出力する処理を記述したファイルをアップロードすることでお好みのアウトプットを得ることができます。(双方ともにアップロードするファイルは.py形式で記述ください)
ファイル名の箇所はポストプロセスで出力されるファイルがある場合にそのファイル名を入力いただく箇所ですので、
ポストプロセスでファイル出力を行わない場合は入力不要となります。
プリプロセスを利用しない場合は、パイプラインを作成後にデータソースのアップロードを行います。
アップロードするファイルを選択し、Uploadを押してください。
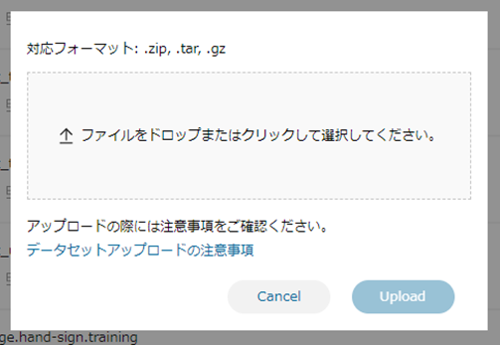
アップロードが完了したら、
トリガーがONになっているデータソース名に対してパイプライン処理が実行されます。
ジョブ実行確認と結果ファイルのダウンロード
パイプラインのジョブ詳細から履歴を参照いただくと、
順次ジョブが実行されていることを確認できます。
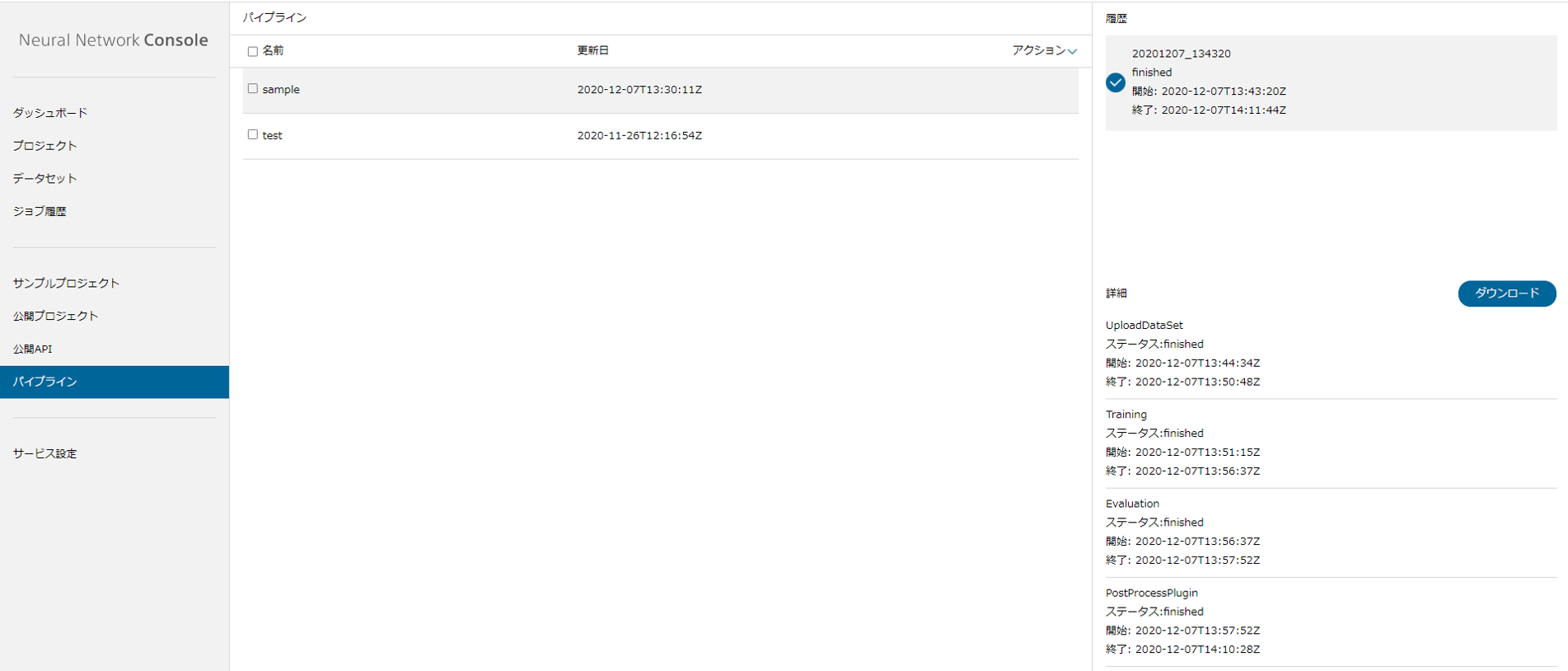
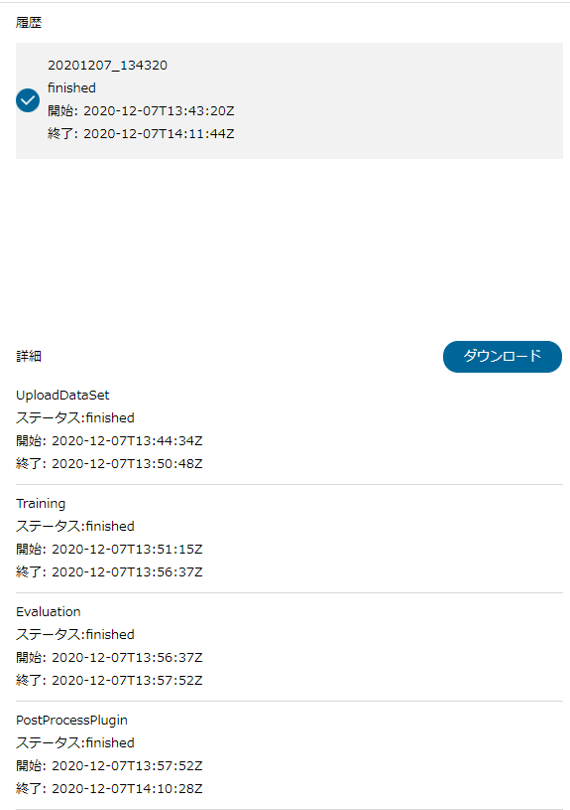
すべてのジョブについてステータスが「finished」になりましたら、
ダウンロードボタンを押すことで、
ポストプロセスで設定した結果ファイルのダウンロードが可能となります。
また、結果メールの通知設定をオンにしていれば、登録されているメールアドレス宛に結果ファイルのダウンロードリンクが送信されます。
こちらのリンクの有効期限はセキュリティ上の観点から24時間のみ有効となります。
(ポストプロセスを設定していなければ、結果ファイル「result.nnp」のダウンロードが可能となります。)