We released Neural Network Console – Windows Version 1.20. In version 1.20 of the Neural Network Console Windows version, many functions were added in response to the feedback received from the users. This blog explains the following new features that were added in version 1.20 of the Neural Network Console Windows version and how to use them.
* Unit function
* Quantize experiment function
* pptx report export function (beta)
* Other functions and improvements
1. Unit function
The unit function makes it possible to recall predefined network structures from the Unit layer for repeated use.
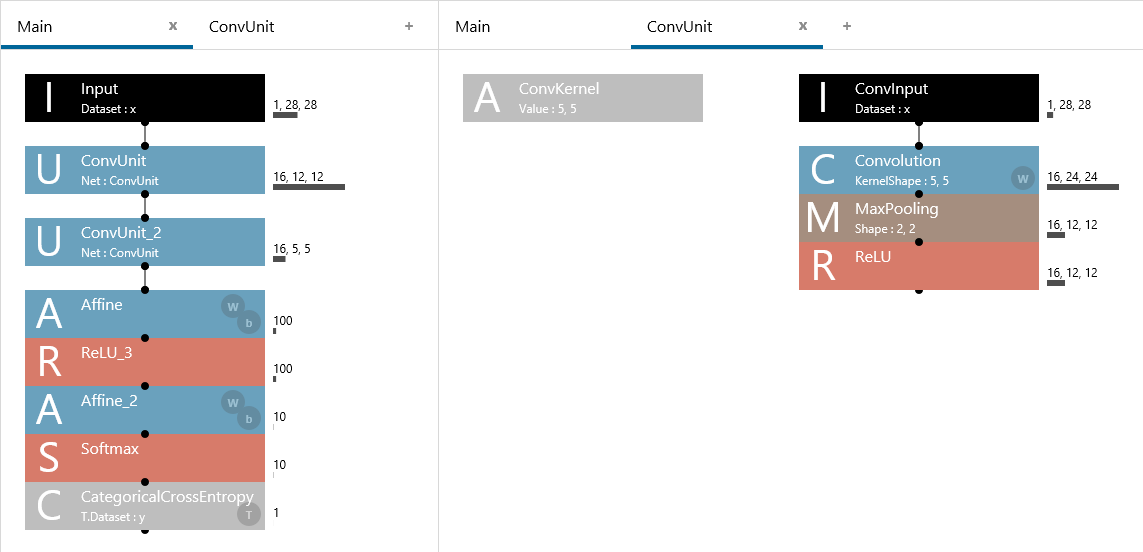 LeNet expression using the unit function
LeNet expression using the unit function
The unit function is analogous to subroutines and functions in programming. In programming, frequently used codes are defined as functions to make them reusable. Likewise, the unit function allows frequently used network structures to be defined as units to make them reusable.
Especially when you are designing a large complex network, the effects of using units become evident, allowing entire networks to be designed with less work, making entire networks easier to view (read), and providing high maintainability.
For details on unit layers, see “Tutorial: Expressing complex networks concisely using the unit function”.
2. Quantize experiment function
The quantize experiment function can be used, for example, to test various quantization settings during training by assuming that a trained neural network will be executed using a DSP or FPGA with low-bit integer computation functions.
The newly added FixedPointQuantize and Pow2Quantize layers in the Quantize category provide linear quantization and power-of-2 quantization functions, respectively. These functions can be inserted after any data path or parameter. Further, you can set any bit length and whether a sign is available at each location.
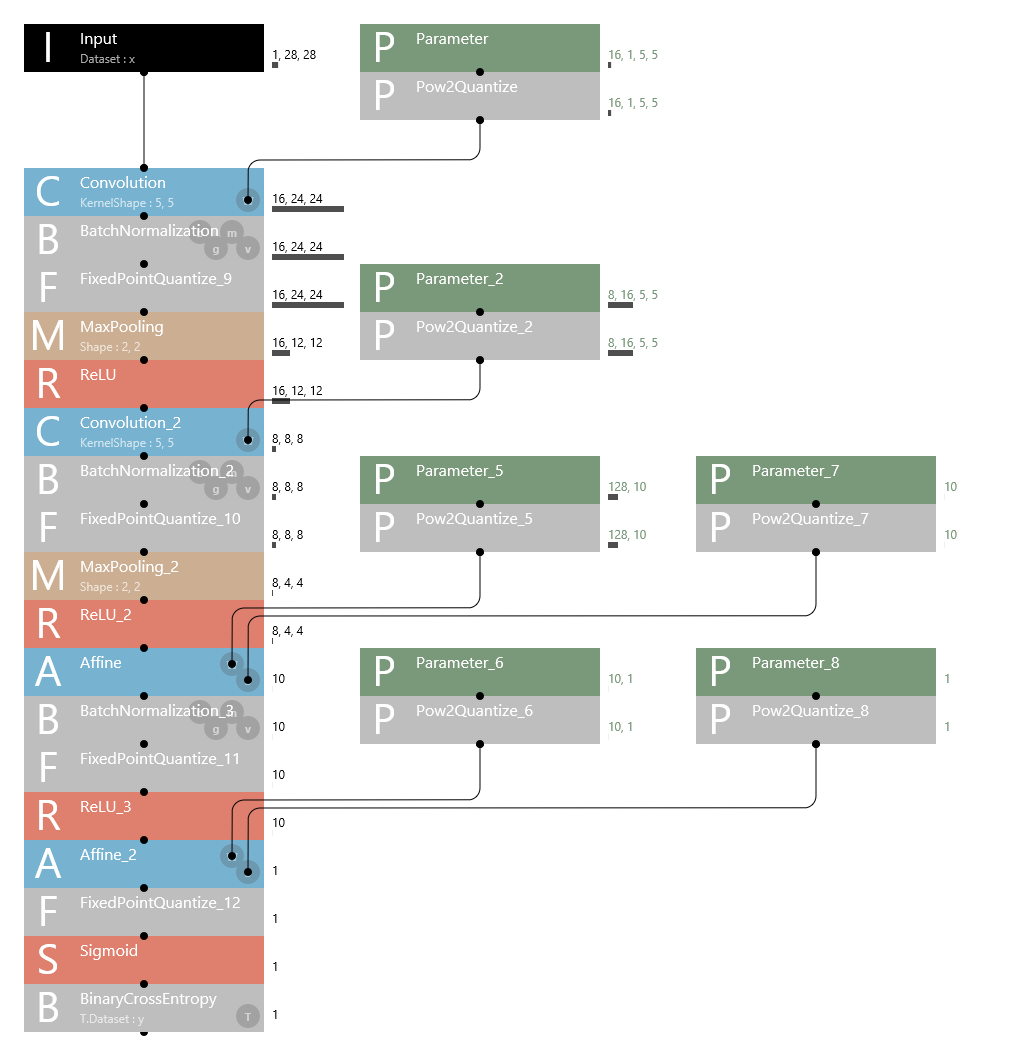 Example of constructing a network using quantization layers
Example of constructing a network using quantization layers
Because quantization layers perform quantization even during training, quantization results are applied not only to forward calculations but also to parameter updates during training. Models trained with quantization layers can be expected to have higher accuracy than when quantization is performed on trained models as a post-process.
This function can be used for a wide variety of purposes such as (1) experiments to clarify the relationship between quantization levels and the performance in various network structures and (2) training to implement network structures that produce high performance with shorter bit length.
3. pptx report export function (beta)
By using the pptx report export function, you can export the results of experiments performed on Neural Network Console as reports in Power Point format.
To use the pptx export function, on the TRAINING or EVALUATION tab, right-click the training result to open a shortcut menu, and click Export, pptx beta.
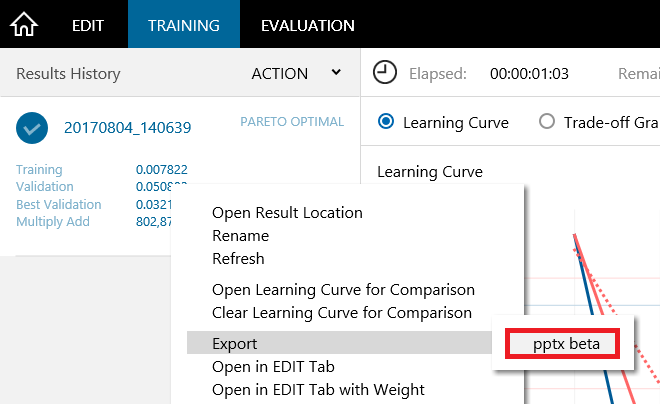 pptx report export
pptx report export
The following is an example of a presentation file created by executing a pptx report export on a LeNet sample project.
 Presentation exported based on a LeNet sample project
Presentation exported based on a LeNet sample project
As shown above, by using the pptx report export function, you can export the dataset used in the experiment, the network structure and training settings, the evaluation results (if evaluation has been performed), and even references to a single presentation file.
The pptx export function is useful not only for recording your own experiments but also for sharing experiment results efficiently.
4. Other information
Version 1.20 of the Neural Network Console Windows version also has other new features and improvements, which are explained below.
nntxt import function
You can now use Neural Network Console to import neural networks that have been designed using the open source Neural Network Libraries and Python API and saved to nntxt format using the save function. With this function, you can now use Neural Network Console to visualize and debug neural networks designed with Neural Network Libraries.
Improvements to automatic structure search
Searching is now possible on a wider variation of network structures. Further, by using the new StructureSearch layer added to the Setting category, you can specify whether to perform a search separately for each network structure (the network tab on the EDIT tab).
Search function using the Components string
When you enter a character string in the text box to the right of Components on the EDIT tab, the layers are filtered using the specified string to display components. This function makes it easier to search for the layers you need.
Links to the Web manual from layers
You can now click the manual icon added to the layer property area to view the layer reference provided on the Web.
Improvements to the create dataset function
The time needed to create datasets using the create dataset function has been greatly reduced. Further, Shaping Mode now provides Resize (resize to the specified size ignoring the aspect ratio) in addition to Trimming and Padding.
Improvement to the compatibility of the caffe prototxt import/export function
Neural Network Console has a function (beta) for importing and exporting caffe-compatible prototxt files. With this update, it is possible to import and export more prototxt files.
Version 1.20 of the Neural Network Console Windows version includes nearly 50 improvements and fixes in addition to those described in this document.
We look forward to hearing your opinions and requests to add more useful functions in the future.
Neural Network ConsoleWindows App
https://dl.sony.com/app/