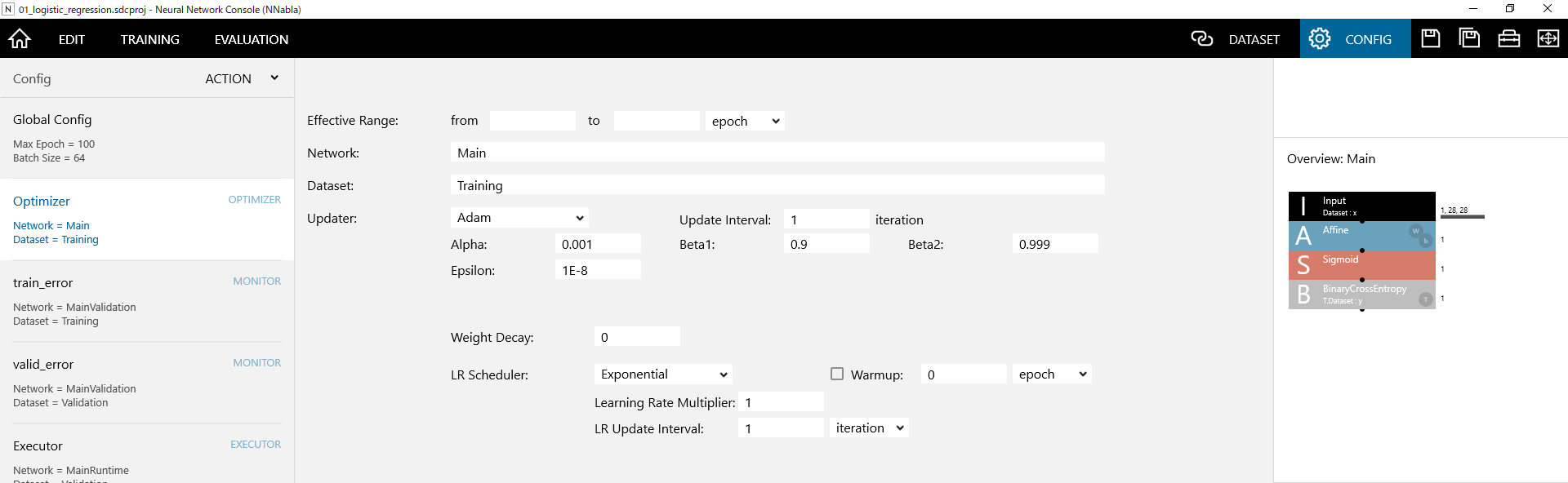
1 Optimizerを有効にする範囲を指定するには
Effective Rangeのfrom、toにそれぞれ有効にする範囲iterationもしくはepoch単位で指定します。
例えば、Optimizerを50 epoch~100 epochまで有効にするには、fromに50、toに100を入力します。1 epoch~Max Epochまで全ての範囲でOptimizerを有効にするには、from、toいずれも空欄にします。
2 最適化に用いるネットワークの名前を指定するには
Networkに編集タブで作成したネットワーク名を指定します。
3 最適化に用いるデータセットの名前を指定するには
Datasetにデータセットタブで読み込んだデータセット名を指定します。Optimizerで複数のデータセットを同時に用いる場合は、複数のデータセットの名前をカンマ区切りで指定します。
4 パラメータのアップデート手法を指定するには
- コンフィグリストからOptimizerを選択します。
- Updaterを以下から選択します(デフォルトはAdam)。
| Updater | 更新式 |
| Adadelta |
$$g_t \leftarrow \Delta w_t\\ Matthew D. Zeiler ADADELTA: An Adaptive Learning Rate Method |
| Adagrad | $$g_t \leftarrow \Delta w_t\\ G_t \leftarrow G_{t-1} + g_t^2\\ w_{t+1} \leftarrow w_t – \frac{\eta}{\sqrt{G_t} + \epsilon} g_t$$ John Duchi, Elad Hazan and Yoram Singer Adaptive Subgradient Methods for Online Learning and Stochastic Optimization |
| Adam | $$m_t \leftarrow \beta_1 m_{t-1} + (1 – \beta_1) g_t\\ v_t \leftarrow \beta_2 v_{t-1} + (1 – \beta_2) g_t^2\\ w_{t+1} \leftarrow w_t – \alpha \frac{\sqrt{1 – \beta_2^t}}{1 – \beta_1^t} \frac{m_t}{\sqrt{v_t} + \epsilon}$$ Kingma and Ba Adam: A Method for Stochastic Optimization. |
| Adamax | $$m_t \leftarrow \beta_1 m_{t-1} + (1 – \beta_1) g_t\\ v_t \leftarrow \max\left(\beta_2 v_{t-1}, |g_t|\right)\\ w_{t+1} \leftarrow w_t – \alpha \frac{\sqrt{1 – \beta_2^t}}{1 – \beta_1^t} \frac{m_t}{v_t + \epsilon}$$ Kingma and Ba Adam: A Method for Stochastic Optimization. |
| AMSGRAD | $$m_t=\beta_1m_{t-1}+\left(1-\beta_1\right)g_t\\ v_t=\beta_2v_{t-1}+\left(1-\beta_2\right){g_t}^2\\ {\hat{v}}_t=max\left({\hat{v}}_{t-1},\ v_t\right)\\ \theta_{t+1}=\theta_t-\alpha\frac{m_t}{\sqrt{{\hat{v}}_t}+\varepsilon}$$ Reddi et al. On the convergence of ADAM and beyond. |
| Momentum | $$v_t \leftarrow \gamma v_{t-1} + \eta \Delta w_t\\ w_{t+1} \leftarrow w_t – v_t$$ Ning Qian On the momentum term in gradient descent learning algorithms |
| Nag | $$v_t \leftarrow \gamma v_{t-1} – \eta \Delta w_t\\ w_{t+1} \leftarrow w_t – \gamma v_{t-1} + \left(1 + \gamma \right) v_t$$ Yurii Nesterov A method for unconstrained convex minimization problem with the rate of convergence o(1/k2) |
| RMSprop | $$g_t \leftarrow \Delta w_t\\ v_t \leftarrow \gamma v_{t-1} + \left(1 – \gamma \right) g_t^2\\ w_{t+1} \leftarrow w_t – \eta \frac{g_t}{\sqrt{v_t} + \epsilon}$$ Geoff Hinton Lecture 6a : Overview of mini-batch gradient descent http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf |
| Sgd | $$w_{t+1} \leftarrow w_t – \eta \Delta w_t$$ |
θ:更新対象のパラメータ
g:勾配
η、α:Learning Rate、Alpha(学習係数)
γ、β1、β2:MomentamもしくはDecay、Beta1、Beta2(Decayパラメータ)
ε:Epsilon(ゼロ除算を防ぐために用いる小さな値)
5 Weight Decay(L2正則化)の強度を設定するには
Weight DecayにWeight Decayの係数を指定します。
6 学習係数の減衰方法を指定するには
- コンフィグリストからOptimizerを選択します。
- UpdaterのLR Scheduler (Learning Rate Scheduler)を以下から選択します(デフォルトはExponential)。
- Linear Warmupを行う場合、Warmupをチェックし、Warmupの長さをiterationもしくはepochで指定します。
| LR Scheduler | 解説 |
| Cosine | 以下の式に従い学習係数を減衰します。 $$\eta_t=\frac{\eta_0}{2}\left(1+cos\left(\frac{t}{T}\pi\right)\right)$$ t:現在までのパラメータ更新回数 |
| Exponential | 学習係数を指数関数で減衰します。 Learning Rate Multiplierに学習係数を減衰させる係数を、LR Update Intervalに学習係数を減衰させる間隔を指定します。 |
Polynomial | 学習係数を以下の多項式で減衰します。 $$\eta_t=\eta_0\left(1-\left(\frac{t}{T}\right)^p\right)$$ Powerにpに用いる係数を指定します。 |
Step | 学習係数を指定するiterationもしくはepoch毎に指定倍に減衰します。 Learning Rate Multiplierに学習係数を減衰させる係数を、LR Update Stepsに学習係数を減衰させるタイミングをカンマ区切りの数値で指定します。 |
7 パラメータの更新を複数回のMini-batchに1回行うには
Update Intervalにパラメータの更新を行う間隔を指定します。例えば64個のデータを含んだMini-batchを用いて4回勾配を計算し、4回のMini-batchごとにまとめてこれらの勾配を用いたパラメータの更新を行うには、Batch Sizeを64、Update Intervalを4とします。
ご注意
複数の学習用ネットワークを用いた最適化を行う場合、Update Intervalには常に1を指定する必要があります。
8 新しいOptimizerを追加するには
メニューボタン、もしくはコンフィグリストを右クリックして表示されるポップアップメニューからAdd Optimizerを選択します。
9 Optimizerの名前を変更するには
- メニューボタン、もしくはコンフィグリストを右クリックして表示されるポップアップメニューからRenameを選択します。
- もしくはコンフィグリストから、名前を変更するOptimizerを2度クリックします。
- 新しい名前を入力してキーボードのEnterキーを押します。
10 Optimizerを削除するには
- コンフィグリストで、削除するOptimizerを選択します。
- メニューボタン、もしくはコンフィグリストを右クリックして表示されるポップアップメニューからDeleteを選択します。
- もしくは、キーボードのDeleteキーを押します。
11 Optimizerを並び替えるには(NNabla)
- コンフィグリストで、並び替えるOptimizerを選択します。
- メニューボタン、もしくはコンフィグストを右クリックして表示されるポップアップメニューからMove Up(上に移動)もしくはMove Down(下に移動)を選択します。